Evolving Intelligence
Author: Vishal Sharma
How evolutionary principles can help you build autonomous systems
The Current State
2025 has been the year of agents. Whereas last year most of the AI conversation revolved around language models, this year that conversation clearly shifted to a new phase: Autonomy. Using tools. Making decisions.
AI agents are quickly transitioning from experiments to production systems across industries. In software development the clearest sign of this has been the rapid adoption of programming assistants such as Cursor and later Claude Code. Meanwhile agents are also feeding into higher-level decision making via research agents capable of searching through vast quantities of unstructured documentation and answering complex questions. Beyond these internal applications they are even finding use in outward-facing roles such as in customer service agents. The spread of AI agents throughout our world is set to continue.
Consider some real-world numbers: IBM unlocked $3.5 billion in cost savings over two years through AI-enabled transformation, achieving a 50% increase in productivity across enterprise operations (BCG, 2025). A global biopharma company reduced clinical report drafting time from 17 weeks to just 5 weeks, a 70% reduction, while cutting marketing agency costs by 20-30% for projected savings of $80-170 million (BCG, 2025). For latency-sensitive applications, the difference is stark: a consumer-packaged goods company reduced marketing campaign reporting from a week-long process requiring six people to less than one hour of automated generation (BCG, 2025).
The Implementation Problem
But it's not all so simple. When we think of AI we are most likely to think of the latest and most capable flagship models of each of the foundation labs: currently Claude 4.1 Opus, GPT-5, Gemini 2.5 Pro, etc. But are these really the models you want in production for your use case? Yes, they're powerful. Yes, they excel at various evals. But are they fast enough? Maybe. And are they cheap? No, not really. And when you're trying to serve a model at scale to power your application, you'll need to find some balance. So, what should you do?
This is an optimization problem. When you have a narrowly defined goal, you don't need the most powerful model in the world to achieve it. Instead, you should consider trading unnecessary capabilities in return for what you really care about: speed and cost-effectiveness. You're not going to need Opus to route customer queries. Recent work from NVIDIA suggests an unexpected route forward: small language models (under 10B parameters) are not just sufficient but often preferable for agentic applications. These models can match larger models on specific tasks while running an order of magnitude faster and cheaper.
For instance, Microsoft's Phi-3 achieves performance comparable to 70B models while running 15× faster, and serving a 7B model costs 10-30× less than a 175B model in terms of latency, energy, and computational resources (Belcak et al., 2025). The key point: most agentic tasks are "repetitive, scoped, and non-conversational", meaning there is a clear use case for models that are efficient, predictable, and inexpensive rather than maximally capable generalists.
The Optimization Challenge
So how should we begin? We want to get more done, and we want it done faster and with lower costs. Here we take inspiration from biology and the field of evolutionary optimization. The power of evolutionary approaches for solving complex multi-objective problems is well-established (Deb et al., 2002), and recent work has shown their effectiveness in optimizing everything from data structures (Basios et al., 2018) to entire AI systems. In fact, evolutionary methods have now reached the point where they can generate expert-level scientific software: AlphaEvolve demonstrates how coding agents can make algorithmic discoveries (Novikov et al., 2025), while recent work from Google DeepMind shows AI systems creating software that outperforms human experts across domains from bioinformatics to epidemiology (Aygün et al., 2025).
To put these ideas into practice, we need a way to measure how well agents actually perform under real-world constraints of speed, cost, and accuracy. That’s where the AtCoder Heuristic Contest Leaderboard Evaluation (ALE) comes in. ALE focuses on heuristic optimization problems: open-ended challenges that mirror the messy tradeoffs faced in production systems. It provides a rigorous testbed for exploring exactly the questions we’ve raised: can smaller, faster models be tuned and evolved into agents that deliver reliable, efficient solutions at scale? Just as importantly, ALE enables direct comparisons with strong human experts and tests whether AI systems can sustain improvement over time, making it a proving ground for long-horizon reasoning and iterative refinement.
What is the ALE Benchmark?
The ALE Benchmark [Imajuku et al., 2024], standing for AtCoder Heuristic Contest Leaderboard Evaluation, represents one of the most rigorous testing environments for AI agents in competitive programming. It focuses on heuristic optimization problems derived from real AtCoder competitive programming contests.
Think of it as the difference between solving a math equation with a single correct answer versus designing the most efficient route for a delivery truck navigating through a bustling city with changing traffic patterns. The latter requires creativity, adaptability, and strategic thinking: exactly what ALE demands from AI agents.
The benchmark consists of 40 challenging test cases that simulate real-world optimization scenarios: pathfinding algorithms that must navigate complex terrains, resource allocation problems that balance competing priorities, and intricate simulations that mirror the unpredictability of actual systems. What makes ALE particularly valuable is its resistance to saturation: these problems are exceptionally difficult to solve optimally, providing significant room for improvement.
The Evaluation Framework
ALE-Bench adopts the evaluation methodology of the AtCoder Heuristic Contests, providing both fine-grained and aggregated metrics to capture AI system performance. At the per-problem level, it records: (i) the raw score produced by the official scorer, (ii) the rank relative to human contestants, and (iii) a derived performance score, an Elo-like rating that normalizes across problems and typically ranges from 0 to 3500, where higher values indicate stronger performance. To summarize results across the benchmark, ALE-Bench reports the average performance (the arithmetic mean across problems) and can compute an AtCoder-style rating. While the rating mirrors human leaderboards, the authors note that average performance is usually more appropriate for AI evaluation, since it avoids distortions from isolated high scores. In addition, ALE-Bench can report acceptance rates, including partial and full acceptance, to reflect practical reliability in producing compiling, runnable solutions.
Our Starting Point: The Baseline Agent
Our journey began with a straightforward approach: a zero-shot implementation using GPT-4o-mini, a lightweight language model optimized for computational efficiency. This baseline agent processed problem descriptions and generated complete solutions through single-inference passes, without iterative refinement or example-based learning.
The baseline performance across five independent evaluation runs revealed both promise and opportunity:
| Metric | Value | Interpretation |
|---|---|---|
| Acceptance Rate | 66.0% | Solid foundation - agent solved approximately two-thirds of problems |
| Average Performance Score | 501.3 ± 38.1 points | Moderate performance with notable variance |
| Average Competitive Rank | 763.8 ± 22.0 | Mid-tier competitive placement |
| Computational Cost | ~$25 per evaluation | Reasonable cost for comprehensive testing |
While these results demonstrated the inherent capability of modern language models for competitive programming, they also highlighted significant room for improvement. Nearly one-third of problems remained unsolved, and the performance variance suggested inconsistent problem-solving strategies.
The Optimization Journey: Evolving Strategies
The true power of ALE emerges when we move beyond static baselines and start evolving strategies for generating solutions. In many ways, this mirrors the process of evolving intelligence itself: variation, selection, and refinement driving incremental but transformative gains.
Path 1: Prompt Optimization
The first optimization strategy focused on evolutionary refinement of the agent's instruction sets. Think of this as teaching a student better problem-solving techniques: instead of changing the student, we refined how we explained the problems and guided the thinking process.
Through systematic mutation and selection processes across five optimization iterations, we explored variations in:
- Problem Comprehension Frameworks
- Constraint Handling Mechanisms
- Solution Generation Strategies
Evolution of Prompts
The optimization process evolved our prompts from simple instructions to sophisticated problem-solving frameworks:
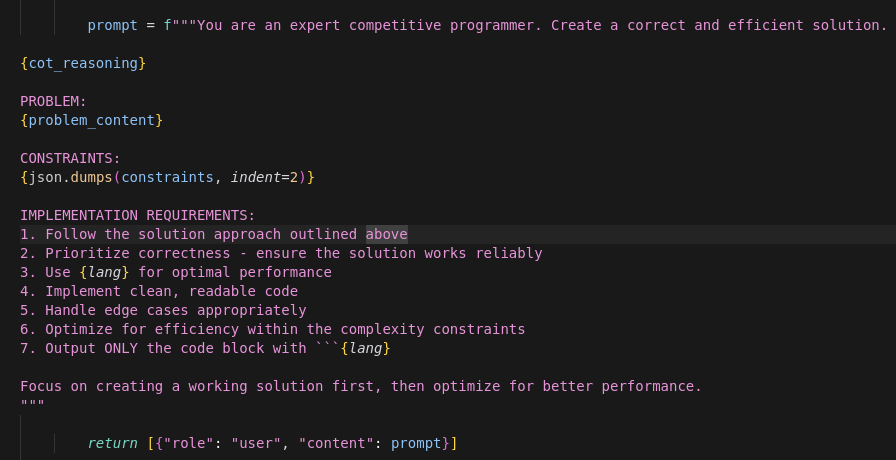 Original baseline prompt: Simple and direct
Original baseline prompt: Simple and direct
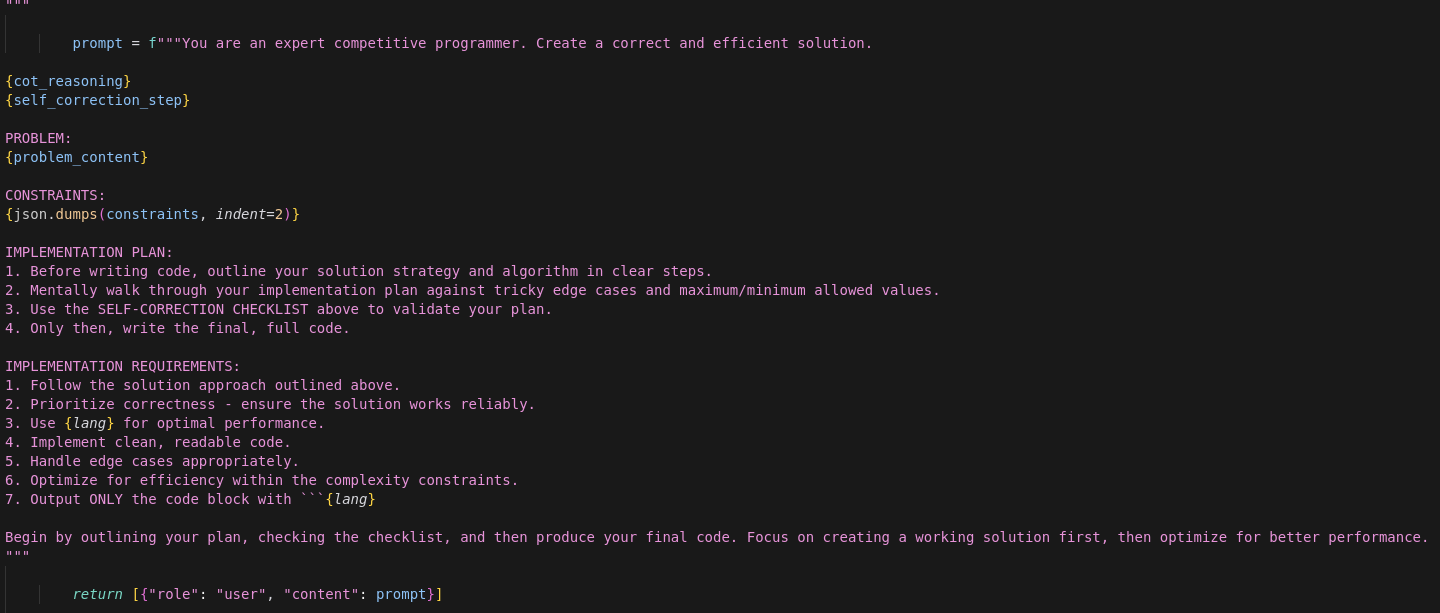 Optimized prompt: Enhanced with self-correction checklist and implementation planning
Optimized prompt: Enhanced with self-correction checklist and implementation planning
The results were remarkable:
- Acceptance Rate: 75.0% (+13.6% over baseline)
- Performance Score: 546.0 ± 61.5 (+8.9%)
- Peak Performance: Best run achieved 82.5% acceptance rate with 33 fully accepted problems
- Cost Efficiency: Maintained ~$25 per evaluation
Solution Quality Comparison
The prompt optimization didn't just improve acceptance rates—it fundamentally transformed how solutions were structured:
 Left: Original solution with basic structure. Right: Optimized solution with improved organization and hash pooling techniques
Left: Original solution with basic structure. Right: Optimized solution with improved organization and hash pooling techniques
Path 2: Search Optimization
The second strategy employed genetic algorithms with variable population sizes and beam search for systematic solution space exploration. Rather than just improving how the agent thinks about problems, this approach enhanced how it explores possible solutions.
Across fifteen optimization configurations, we tested different evolutionary parameters including various generation strategies and population dynamics. This method focused on:
- Solution Space Coverage
- Evolutionary Selection Pressure
- Population Dynamics
Search Algorithm Evolution
The search optimization explored different algorithmic approaches to solution generation:
 Comparison of A search (left) and Genetic Algorithm (right) approaches*
Comparison of A search (left) and Genetic Algorithm (right) approaches*
 Taboo search (left) vs Parallel search optimization (right) strategies
Taboo search (left) vs Parallel search optimization (right) strategies
The results showed:
- Acceptance Rate: 72.2% (+9.3% over baseline)
- Performance Consistency: 530.9 ± 31.2 points with reduced variance
- Computational Efficiency: 29% reduction in runtime
- Cost Optimization: ~$24 per evaluation
Comparative Analysis: Understanding the Evolution
Our analysis revealed fascinating insights into how different optimization approaches evolve solution strategies in competitive programming:
- Problem ahc007: Baseline failed and was generally unable to produce solutions that completed in time. Both optimizations transformed this into consistent acceptance, scores jumping from -61 to 669 (+730 points).
- Problem ahc009: Baseline failed with runtime errors. Prompt optimization fixed this, achieving acceptance and boosting scores from 42 to 584 (+542 points).
These optimizations improved not just results, but fundamental capabilities:
- Enhanced Problem Understanding
- Improved Algorithm Selection
- Better Error Handling
- Time Complexity Awareness
- Stronger Constraint Satisfaction
Each of these reflects an evolutionary step: agents mutate their approach, are evaluated against selective pressure (the benchmark), and the most effective traits persist. Over time, this looks less like tuning parameters and more like the emergence of intelligent behavior.
Impact and Future Directions
Quantitative Achievements
- +13.6% acceptance rate improvement
- 13.9% faster runtime with reduced variance
- Under $26 per evaluation cost maintained
Qualitative Enhancements
- More transparent reasoning
- More robust, reliable solutions
- Systematic exploration of solution spaces
- Smarter algorithm selection
These results demonstrate the gradual emergence of more intelligent solution strategies, echoing the process of evolution in nature.
Summary
Our journey through ALE Benchmark optimization demonstrates not only that systematic enhancement of AI agents is possible, but also how a tool like Artemis can make this process accessible and repeatable. By framing prompt and search optimization as evolutionary paths, Artemis helps teams experiment with variation, apply selective pressure through benchmarking, and retain the best-performing strategies.
In this light, what we are really evolving are not just solutions to individual problems, but strategies for problem solving itself. Over time, this iterative refinement looks very much like the evolution of intelligence.
By turning consistently failing problems into successful solutions, Artemis shows its value as a platform for bridging theory and practice: giving teams a way to discover, test, and refine optimization strategies in a rigorous environment. Looking ahead, Artemis positions developers to create more sophisticated, reliable, and efficient AI systems capable of tackling the complex challenges that define competitive programming and real-world problem-solving scenarios.
References
- Aygün, E., Belyaeva, A., Comanici, G., et al. (2025). "An AI system to help scientists write expert-level empirical software." arXiv preprint arXiv:2509.06503.
- Basios, M., Li, L., Wu, F., Kanthan, L., & Barr, E. T. (2018). "Darwinian data structure selection." In Proceedings of the 2018 26th ACM Joint Meeting on European Software Engineering Conference and Symposium on the Foundations of Software Engineering (pp. 118-128).
- Belcak, P., Heinrich, G., Diao, S., Fu, Y., Dong, X., Muralidharan, S., Lin, Y. C., & Molchanov, P. (2024). "Small Language Models are the Future of Agentic AI." arXiv preprint arXiv:2406.02153.
- "How Four Companies Capitalize on AI to Deliver Cost Transformations." BCG, July 28, 2025.
- Deb, K., Pratap, A., Agarwal, S., & Meyarivan, T. A. M. T. (2002). "A fast and elitist multiobjective genetic algorithm: NSGA-II." IEEE Transactions on Evolutionary Computation, 6(2), 182-197.
- Imajuku, Y., Horie, K., Iwata, Y., Aoki, K., Takahashi, N., & Akiba, T. (2024). "ALE-Bench: A Benchmark for Long-Horizon Objective-Driven Algorithm Engineering." arXiv preprint arXiv:2406.09050.
- Novikov, A., Vũ, N., Eisenberger, M., et al. (2025). "AlphaEvolve: A coding agent for scientific and algorithmic discovery." arXiv preprint arXiv:2506.13131.