Feature Generation with Artemis and evoML
Author: Mina Ilieva
Artemis as a feature generation tool.
The future of data science is merging with generative AI. Provided with the right tooling, agents can not only build models, but optimise their performance and use their domain knowledge to search for highly interpretable predictive features. Here we demonstrate how Artemis Intelligence’s genetic algorithm can intelligently drive this process, at the example of a crucial step in the ML workflow: feature generation.
Feature generation is the process of transforming raw data into meaningful input features to improve model performance. This process can be as straightforward as applying an appropriate encoding scheme to a categorical variable, or standardizing a numerical feature to a particular scale. But often what is required is much more complex dataset expansion, involving engineering new features as the product of an interaction between other features, or adding and creating completely new, domain-relevant data to aid the model in extracting meaningful contextual information, as we balance noise to prevent overfitting and are mindful of data leakage. Here we describe how a data scientist can use Artemis to generate such complex new features for their model(s), with the aim of boosting the performance of a linear model, as a post-hoc analysis method.
This project's initial objective is to build models that can classify whether a customer is likely to obtain the status of serious delinquency in two years, using their credit history data. The end-to-end baseline analysis of this project can be seen here.
Here and throughout this use case, we utilise the our evoML python client package, which enables interaction with our our AutoML platform, but the example can be reproduced with any script which triggers model building and evaluation.
Prerequisites
1. Project environment
A minimal setup for this includes:
- A script that 1.) loads your dataset , 2.) with a custom feature engineering template function* 3.) applies modelling, printing the models’ loss values. This step is crucial for tracking model performance during feature generation, using our runner. This should represent your baseline. Here we have used three models, registered in the EvoML palatform - an xgboost classifier, a lightgbm classifier and a linear regression classifier, with an ROC AUC objective.
*This function would just serve as template for Artemis and could be used to control the degree of complexity for your new features.
def engineer_features(df: pd.DataFrame) -> pd.DataFrame:
"""
Template function for feature engineering.
Args:
df (pd.DataFrame): Input dataframe
Returns:
pd.DataFrame: DataFrame with new features
"""
# Create a copy to avoid modifying the original dataframe
df_engineered = df.copy()
feature_2 = df_engineered.columns[1]
feature_3 = df_engineered.columns[2]
# Example of creating a new feature by multiplying two existing features
#df_engineered["feature_1"] = df_engineered[feature_3] + df_engineered[feature_2]
return df_engineered
df = engineer_features(df)
print(df.columns)
- An .md file for presenting embeddable context to the data prior to preprocessing, describing feature types, and providing context to the target. Below is an outline of the dataset we have used for this example, which is readily downloadable here.
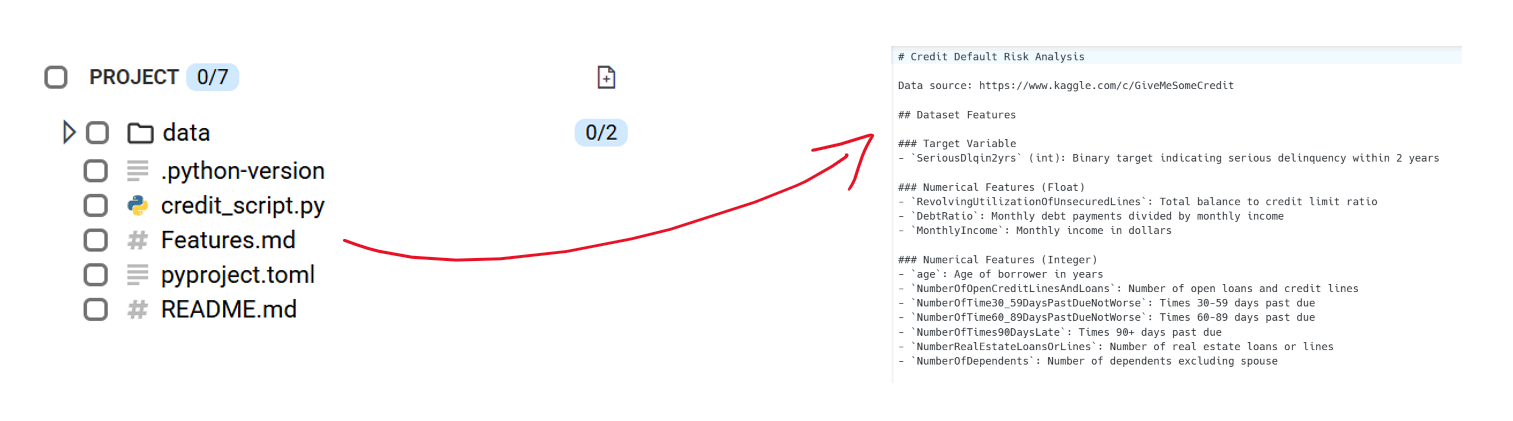
- Project setup
- A running instance of your Artemis Runner for real-time baseline and variant execution and validation.
- A bechmark command to execute your script which will print the model's objective result to the logs. This allows Artemis Intelligence to consume this output and adapt subsequent iterations to your stated goal (prompt).
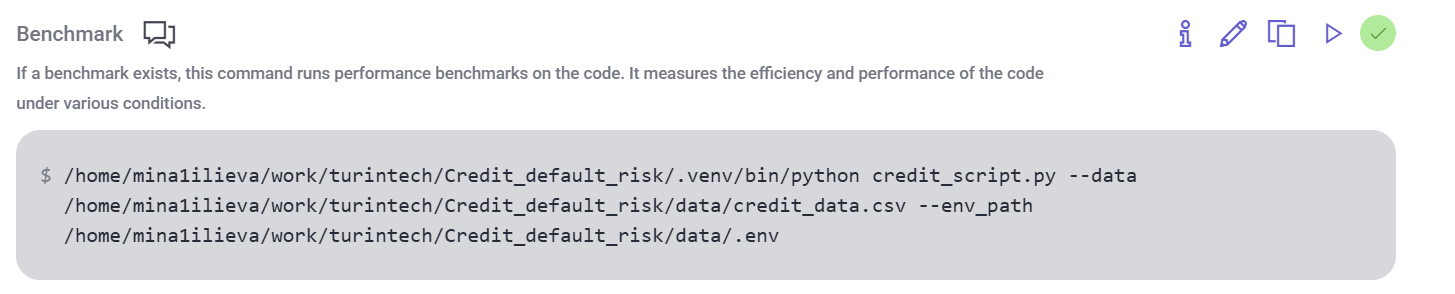
Step-by-step instructions.
1. Validate your benchmark command on Artemis via executing it with the runner. This would serve as your seed program for the recommendation trial.
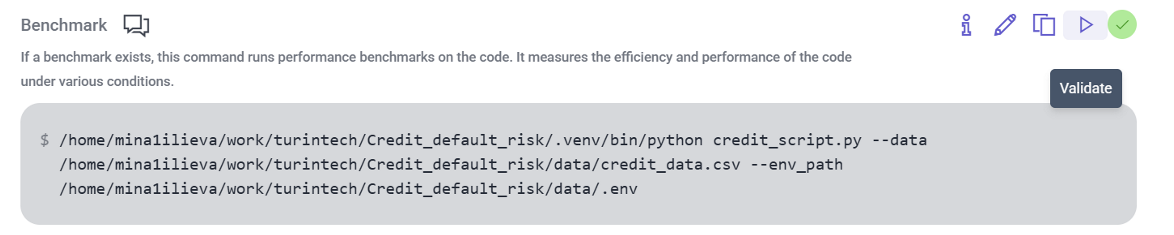
For a clear reference, this is how our our credit default risk use case output looked like:

2. Create a snippet from the baseline script you will be executing.
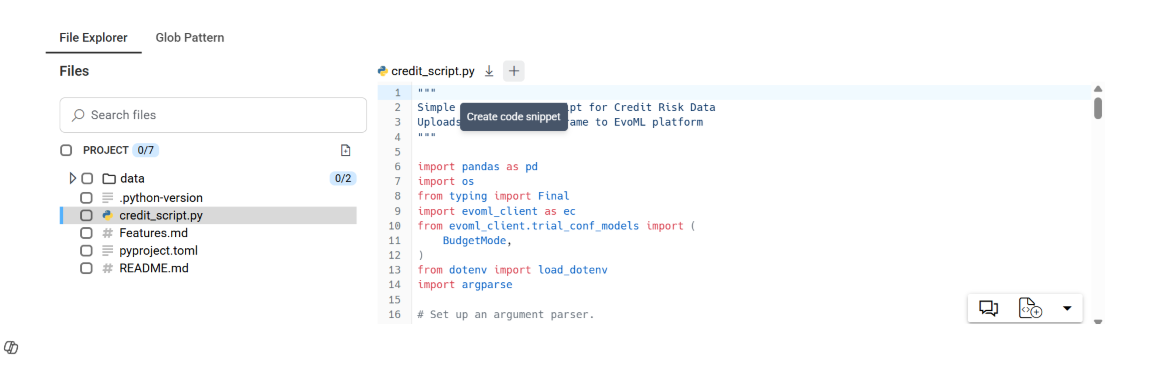
3. Tell Artemis your objective and hit go!
You should provide your a markdown file for reference to the algorithm, choose your LLMs, and allow for your runner to execute the build command ('Configuration'). You also have control over the population count. When this is configure dyou can start your recommendation task. Artemis derives fitness metrics from the logs produced by the task and uses them as the functional guidelines to score candidates, prune each generation and propagate the top-performing individuals to the next population. During this selection, Artemis not only ensures that your code is runnable but that that it also successfully boosts (in our case) the value of your objective.
We were aiming at boosting our linear model's performance. Our prompt looked like this:
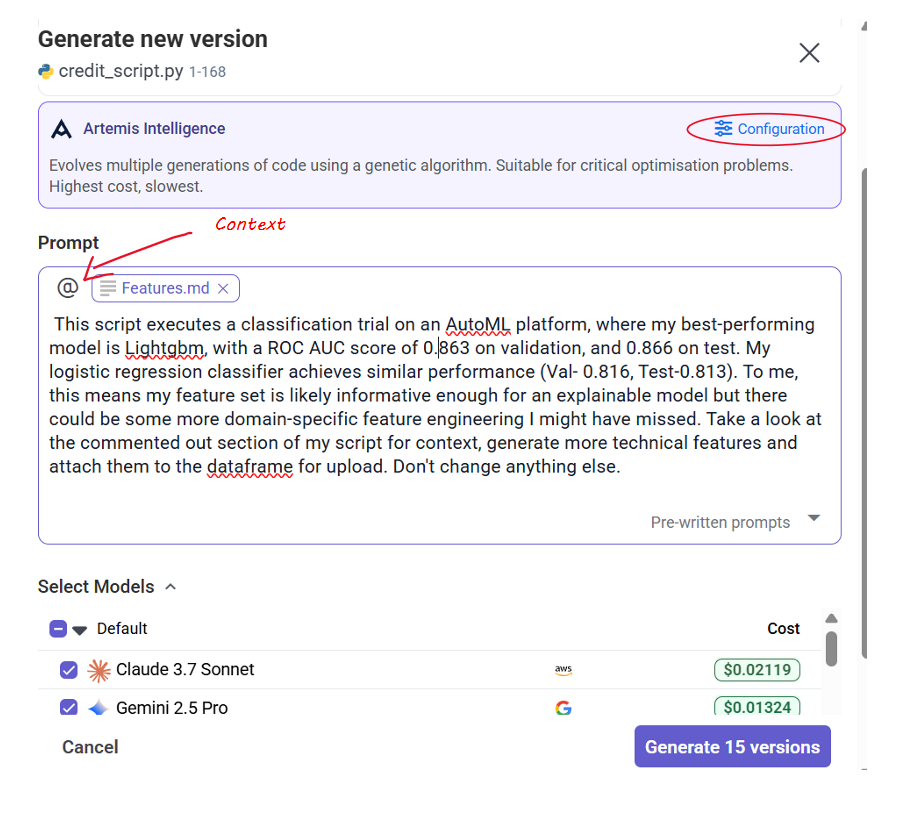
4. Our results
Artemis successfully boosted the performance of our logistic regression classifier, by insightfully engineering new features into our dataset, enabling us to derive even more meaningful insights for our trial. We visualise these with the help of EvoML:
Baseline results:
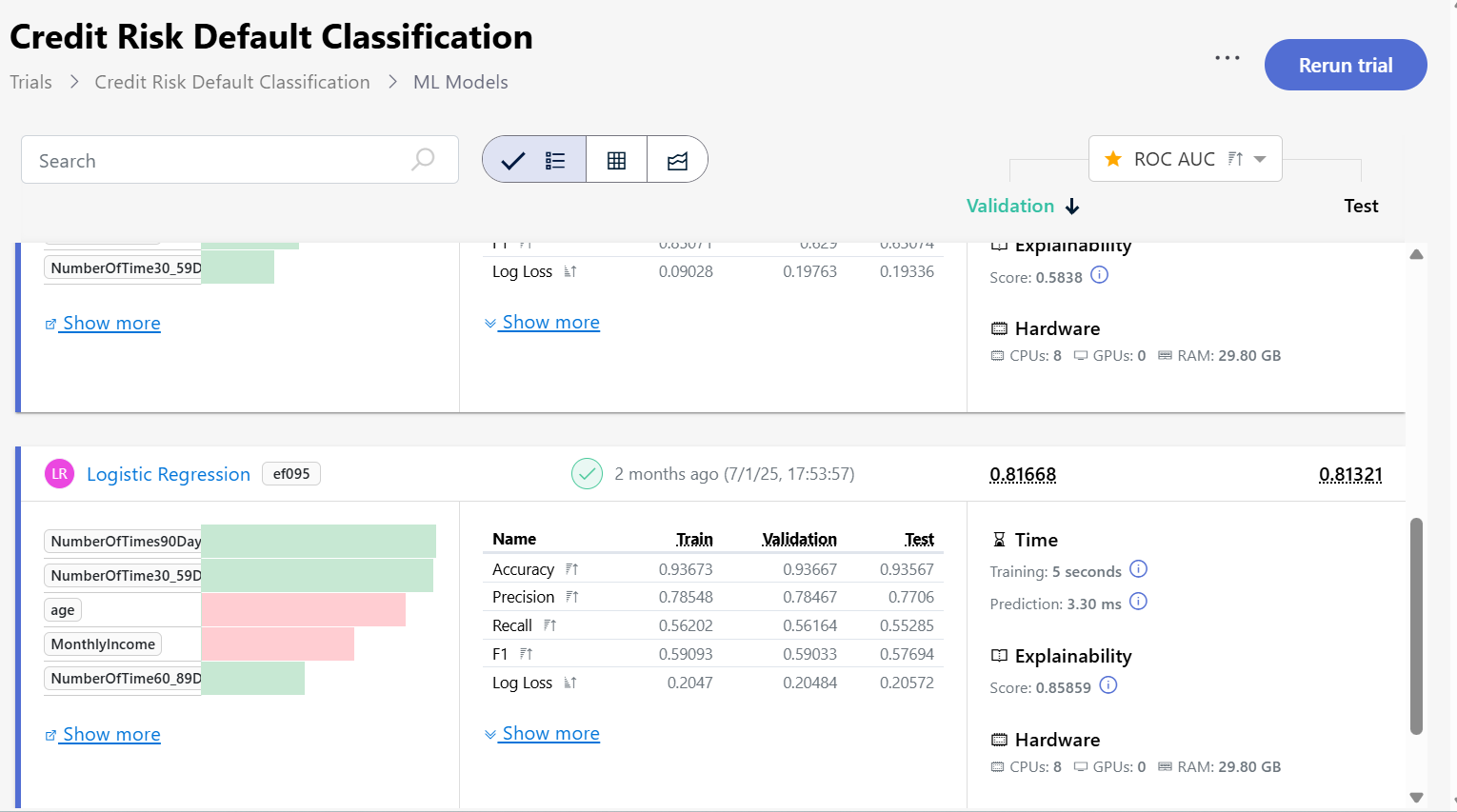
Results from final variant:
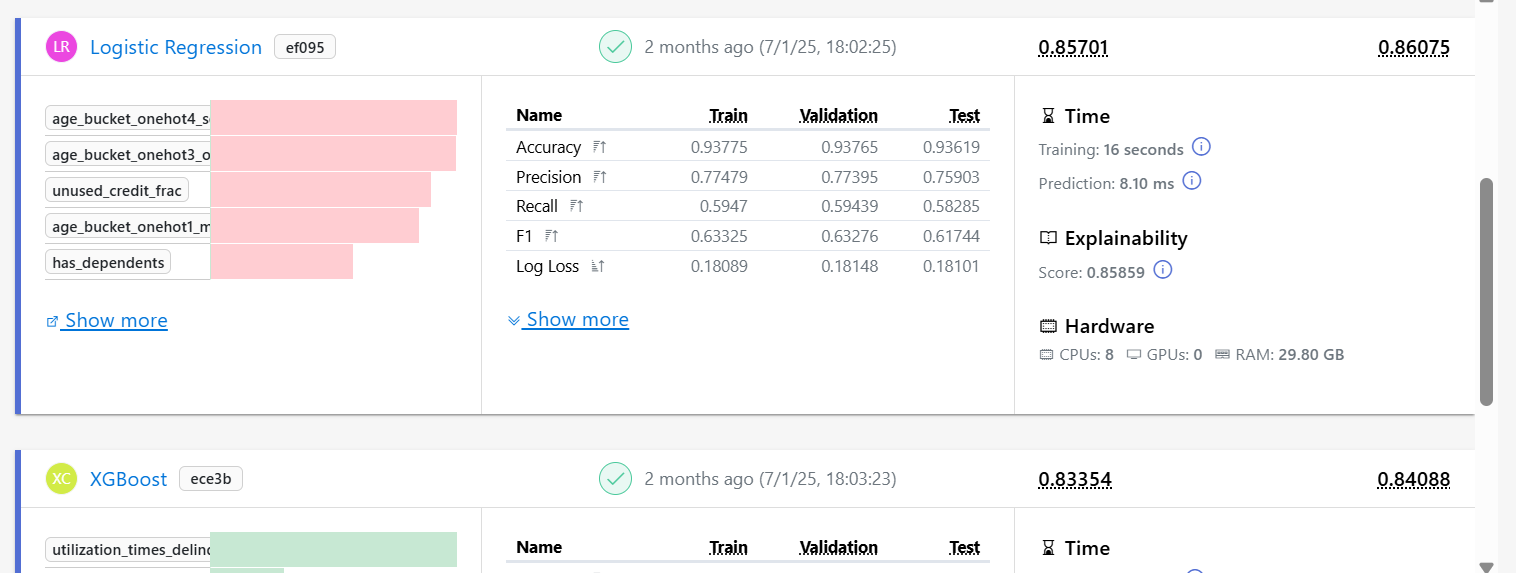
Artemis iteratively improved model discrimination (ROC AUC): +0.04 on validation and +0.50 on test, relative to the baseline.
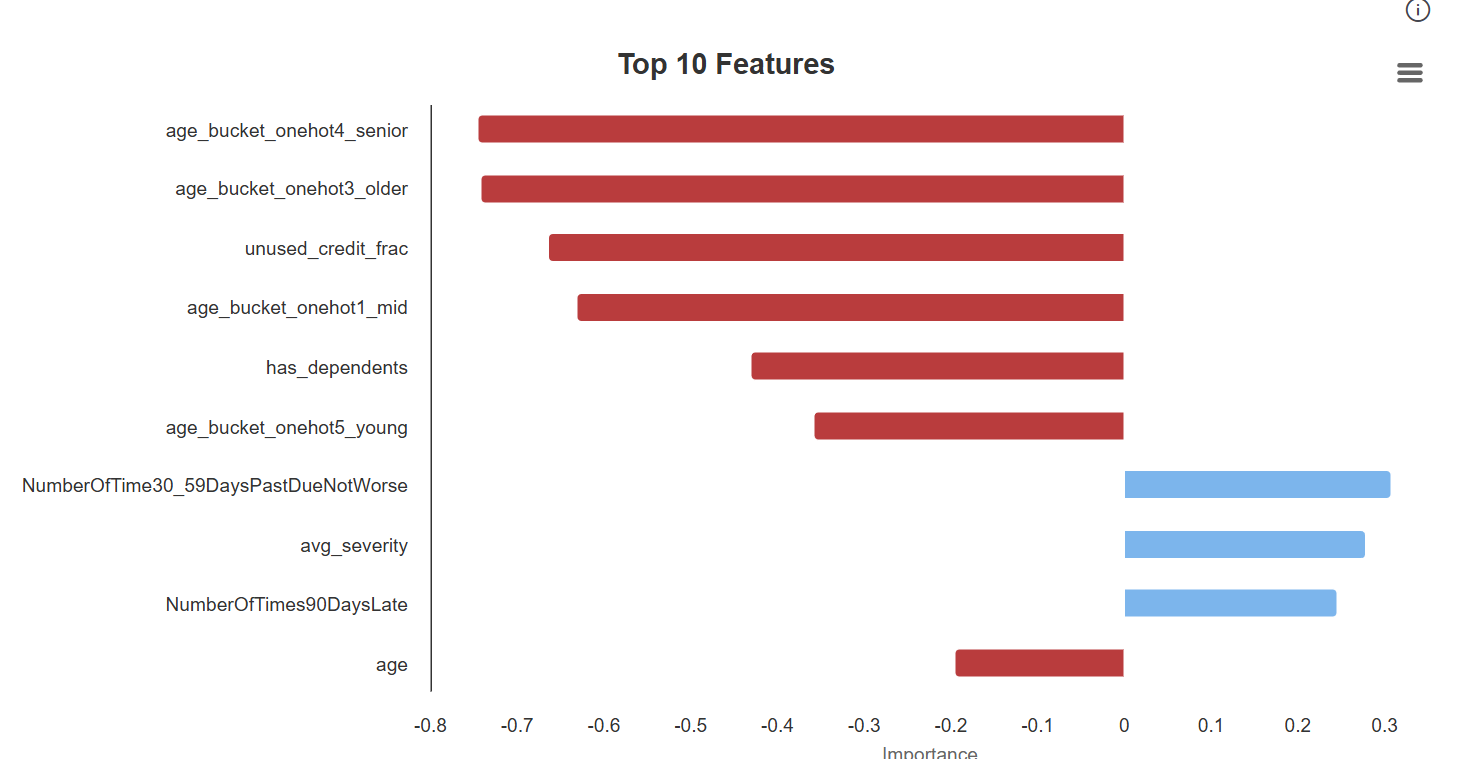 In our Feature Importance tab for the respective model, we see that the age-bucket features generated by Artemis improve explanatory power; their average contribution to the positive (serious-delinquency) class is negative—consistent with age being protective—yet they enhance ranking performance (higher ROC AUC) by sharpening separation across risk strata.
In our Feature Importance tab for the respective model, we see that the age-bucket features generated by Artemis improve explanatory power; their average contribution to the positive (serious-delinquency) class is negative—consistent with age being protective—yet they enhance ranking performance (higher ROC AUC) by sharpening separation across risk strata.
Artemis Chat
How many features did Artemis create? We can always ask:
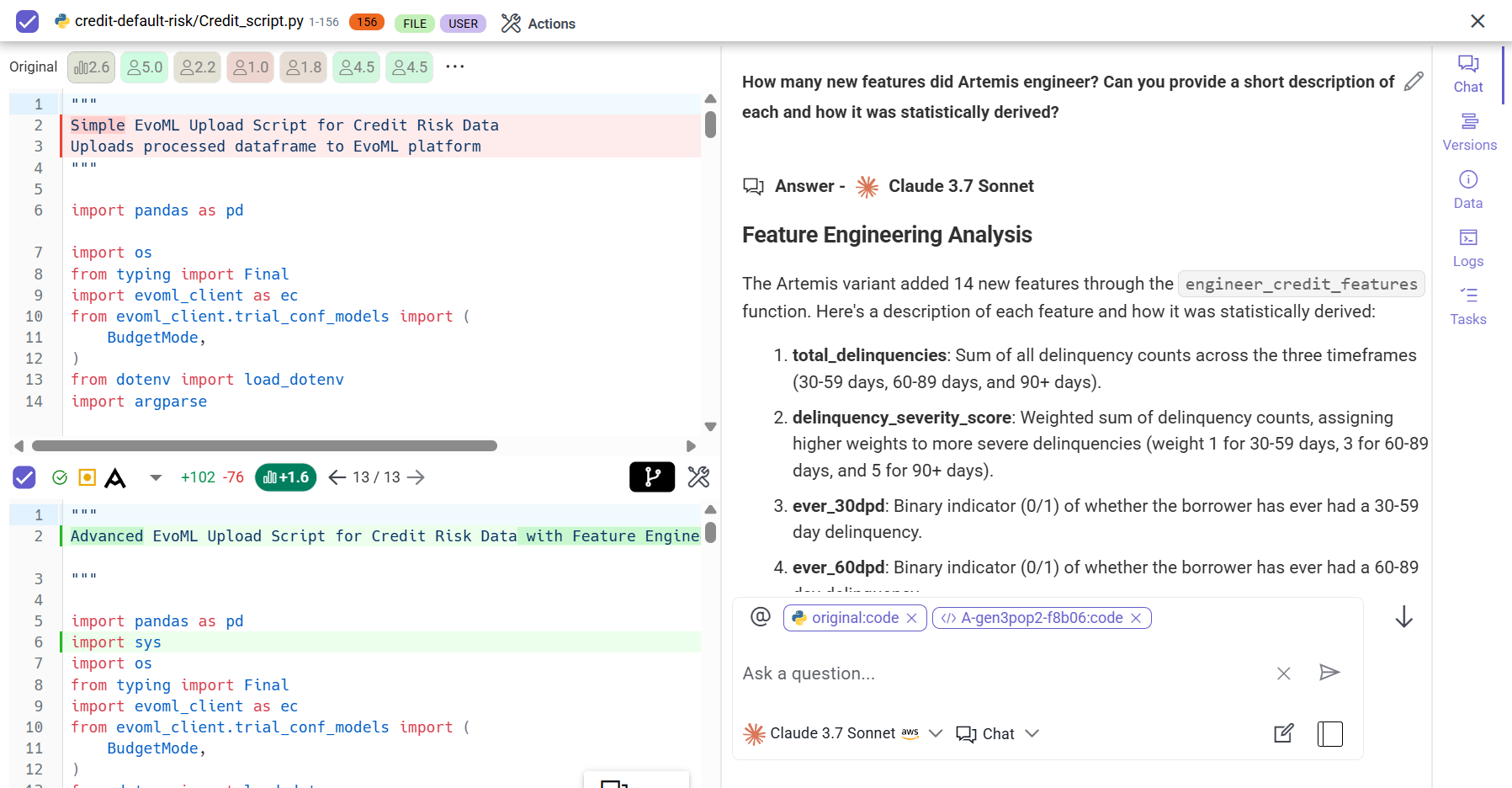
Artemis created those 14 new features by applying domain knowledge about credit risk factors and using statistical transformations such as sums, ratios, thresholds, and interaction terms to extract meaningful signal from the original data. EvoML then encoded these features in a type‑aware, leakage‑safe manner (e.g., one‑hot/target encoding for categorical buckets, scaling for continuous variables, ordinal/monotonic encodings where appropriate), handled missingness, and ensured consistent transformations across train/validation/test splits.
Users who handle those types of data transformation themselves can always specify their preferences in a new recommendation trial, and can also handle further code transformations to their script in a zero-shot or agentic manner.

So there you have it! By giving your model building script to the Artemis Intelligence we can automatically leverage the domain knowledge of these models to generate new model strategies while at the same time using rigorous metrics to provide feedback and guide the optimiser to the best solution.