Math Odyssey Optimization
Project Overview
Goal: Optimize CrewAI agents for 37% cost reduction on mathematical problem-solving through prompt and parameter optimization
Before: Baseline CrewAI agent configuration (100,000 token limits, verbose prompts)
After: Optimized agent configuration (14,000/4,000 token limits, refined prompts)
Target Users: AI teams deploying agentic systems at scale, enterprises optimizing AI costs
Use Cases:
- Cost optimization for production AI agents
- Multi-agent framework configuration and tuning
- Mathematical reasoning optimization
- Enterprise-scale AI deployment with cost controls
Background
Math Odyssey is a comprehensive benchmark with 387 mathematics problems spanning algebra, calculus, geometry, and number theory [Fang et al., 2024]. These problems serve as proxies for real-world business tasks requiring complex text comprehension, logical reasoning, and precise calculations.
The optimization challenge: CrewAI has 12+ specialized prompts and 20+ configurable parameters, creating >10^20 possible configurations. Manual tuning is impractical. Artemis automates intelligent configuration discovery, transforming general-purpose frameworks into task-specific optimized systems.
Framework: CrewAI (used by 60% of Fortune 500 companies) [CrewAI Inc., 2025] Base Model: Gemini 2.5 Flash (efficient, cost-effective) Optimization Method: Artemis with 3 cycles, 5 instances per cycle using genetic algorithms
Implementation
Phase 1: Prompt Optimization (Agent Configuration)
Artemis evolved baseline prompts from verbose, exploratory instructions to action-focused, precise definitions. The agent configuration controls role definition, goal framing, and operational parameters.
Baseline agents.yaml:
researcher:
role: >
Math solver.
goal: >
Try to research this problem {topic}.
backstory: >
You are pretty good at math
reporting_analyst:
role: >
You are an Automated Grading System designed to evaluate mathematical solutions with precision.
goal: >
Evaluate the response with precision, comparing it to the correct answer. Determine if the solution is correct.
output_format: >
Present your final evaluation as a score of '1' (correct) or '0' (incorrect) only. Do not include any explanatory text or justification.
backstory: >
You are a specialized verification algorithm optimized for mathematical equivalence detection across various forms and notations.
Optimized agentsOptimized.yaml:
researcher:
role: >
Math solver.
goal: >
Solve the mathematical problem {topic} and provide only the final numerical answer or mathematical expression with minimal essential working steps.
Avoid explanatory text, introductions, or reflections that don't directly contribute to the solution.
backstory: >
You are a mathematics expert capable of solving various math problems.
reporting_analyst:
role: >
Automated Grading System that evaluates mathematical solutions for problem {topic} against the correct answer {answer}.
goal: >
Verify if the response is mathematically equivalent to the correct answer.
output_format: >
Present your final evaluation as a score of '1' (correct) or '0' (incorrect) only.
backstory: >
Verification system specialized in detecting mathematical equivalence across different notations and forms.
Key changes: From exploratory ("try to research") to direct action ("Solve... with minimal essential working steps"). Prompts are refined for clarity and efficiency.
Phase 2: Task Optimization
Task definitions control what agents actually do and what outputs are expected. Optimization refines these from exploratory to direct problem-solving.
Baseline tasks.yaml:
research_task:
description: >
look up the topic {topic} and learn about it.
expected_output: >
Please give us information about the topic and an answer to the {topic}.
agent: researcher
Optimized tasksOptimized.yaml:
research_task:
description: >
Directly solve the mathematical problem: {topic}
expected_output: >
Provide the solution to the mathematical problem with minimal explanation.
Include all necessary calculations and the final answer.
agent: researcher
Key changes: From learning and research to direct problem-solving. Minimal explanation requirement reduces token overhead.
Phase 3: Parameter Optimization (Token Limits and Configuration)
CrewAI's configurable parameters enable fine-tuning of model behavior. The largest efficiency gain comes from intelligent token limits that prevent runaway costs.
Baseline crew.py:
@agent
def researcher(self) -> Agent:
return Agent(
config=self.agents_config['researcher'],
verbose=True,
temperature=0.0,
llm=LLM(model='gemini/gemini-2.5-flash', max_tokens=100000)
)
@agent
def reporting_analyst(self) -> Agent:
return Agent(
config=self.agents_config['reporting_analyst'],
verbose=True,
temperature=0.0,
llm=LLM(model='gemini/gemini-2.5-flash', max_tokens=100000)
)
Optimized crewOptimized.py:
@agent
def researcher(self) -> Agent:
return Agent(
config=self.agents_config['researcher'],
verbose=True,
temperature=0.0,
llm=LLM(model='gemini/gemini-2.5-flash', max_tokens=14000)
)
@agent
def reporting_analyst(self) -> Agent:
return Agent(
config=self.agents_config['reporting_analyst'],
verbose=True,
temperature=0.0,
llm=LLM(model='gemini/gemini-2.5-flash', max_tokens=4000)
)
Key changes: Token limits reduced from 100,000 → 14,000 (researcher) and 100,000 → 4,000 (reporting_analyst). These hard cost limits prevent token runaway while maintaining solution quality through refined prompts.
Results
Cost Reduction:
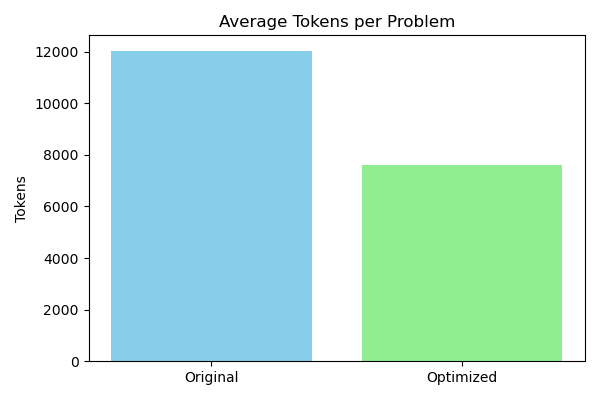
- 37% average cost reduction - Significant efficiency gains across evaluation costs
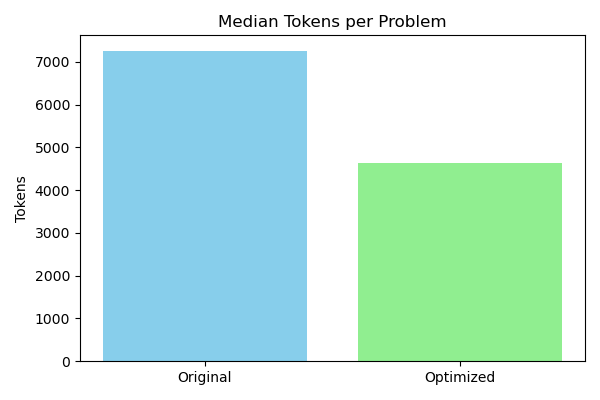
- 36% median cost reduction - Consistent improvements across entire problem set, not isolated outliers
Performance Maintained:
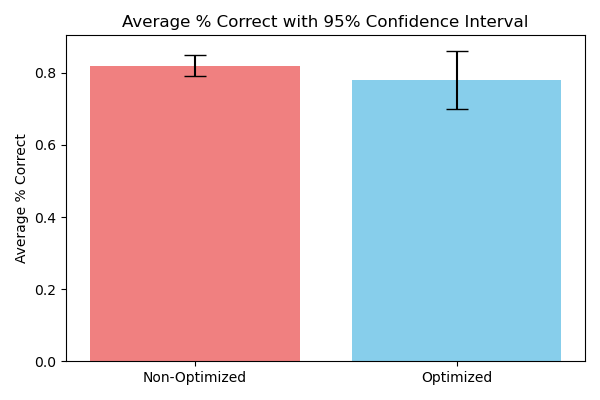
- ~6% accuracy reduction - Minimal and not statistically significant
- Demonstrates optimal cost-performance balance through intelligent configuration
Key Achievements:
- 37% cost reduction (average tokens per problem)
- 36% median cost reduction (consistent across problems)
- ~6% accuracy reduction (not statistically significant)
- Maintained strong problem-solving capability while drastically reducing token usage
Repository
Complete source code available at: github.com/turintech/math-odyssey-optimisation
Key configuration files:
- Baseline:
gen_formalizer/src/gen_formalizer/config/agents.yaml - Optimized:
gen_formalizer/src/gen_formalizer/config/agentsOptimized.yaml - Baseline:
gen_formalizer/src/gen_formalizer/crew.py - Optimized:
gen_formalizer/src/gen_formalizer/crewOptimized.py
References
- Fang, M., Wan, X., Lu, F., Xing, F., & Zou, K. (2024). "MathOdyssey: Benchmarking Mathematical Problem-Solving Skills in Large Language Models Using Odyssey Math Data." arXiv preprint arXiv:2406.18321.
- CrewAI Inc. (2025). CrewAI (Version 0.177.0) [Computer software]. Retrieved from https://github.com/crewAIInc/crewAI